
La dépendance critique des géants de la tech aux fournisseurs cloud : comprendre un risque devenu structurel
La dépendance critique des géants de la tech aux fournisseurs cloud : comprendre un risque devenu structurel
Introduction
Le paysage numérique mondial repose sur une idée simple : externaliser ce qui est trop coûteux ou trop complexe à gérer en interne.
Les géants de la tech ont été les premiers à adopter cette approche, en s’appuyant sur des infrastructures cloud à grande échelle pour déployer leurs services, assurer leur sécurité ou absorber des volumes de trafic colossaux.
Cette stratégie a permis une accélération de l’innovation, mais elle a aussi créé une dépendance profonde et parfois mal comprise vis-à-vis de quelques fournisseurs majeurs.
Aujourd’hui, un incident touchant l’un de ces acteurs peut impacter simultanément des milliers d’entreprises, y compris celles qui disposent des infrastructures les plus avancées.
La centralisation d’un écosystème qui se voulait distribué
Le cloud avait été imaginé comme un modèle distribué et résilient. Pourtant, au fil des années, une centralisation progressive s’est opérée autour d’un groupe restreint de fournisseurs offrant des services spécialisés : compute, stockage, sécurité, DNS, réseaux de diffusion, solutions d’authentification. Pour certains services, un ou deux acteurs captent quasiment tout le marché.
Ce phénomène a transformé ces fournisseurs en points névralgiques de l’internet moderne. Dès qu’un maillon critique rencontre une défaillance, c’est une part disproportionnée du web qui ralentit, se dégrade ou s’interrompt.
Cette concentration ne concerne pas seulement les infrastructures techniques, mais également les outils de développement, les services d’IA, les chaînes CI/CD, les plateformes de communication ou de paiement. De nombreuses entreprises, même très technologiquement avancées, n’ont plus qu’une visibilité partielle sur les dépendances indirectes intégrées par leurs outils ou partenaires.
L’illusion de la redondance totale
À première vue, les géants de la tech semblent protégés contre les interruptions grâce à leurs architectures distribuées, leurs datacenters multiples et leurs procédures de basculement. La réalité est plus nuancée.
La redondance sur laquelle repose l’internet moderne est souvent limitée à l’intérieur d’un même périmètre : plusieurs régions d’un même cloud provider, plusieurs zones protégées par un même opérateur réseau, ou plusieurs instances supportées par une même couche d’authentification.
Dès que cette couche commune connaît une défaillance, toutes les redondances internes deviennent invisibles. Un service peut disposer de serveurs parfaitement opérationnels, mais rester indisponible parce qu’un fournisseur tiers ne peut plus acheminer, résoudre ou authentifier le trafic. Cette asymétrie entre ce que l’entreprise contrôle et ce qu’elle externalise est l’une des fragilités les plus souvent sous-estimées.
Un écosystème d’interdépendances souvent invisibles
Le fonctionnement réel d’un service moderne s’apparente à une chaîne complexe d’acteurs connectés. Une application peut reposer sur un fournisseur cloud, qui lui-même utilise un réseau d’optimisation, qui dépend à son tour d’un registre DNS ou d’une autorité de certification, elle-même hébergée dans un autre cloud. Ces dépendances ne sont pas toujours documentées, et les entreprises ignorent parfois qu’elles sont vulnérables à des incidents survenus plusieurs couches plus loin que leurs propres contrats de service.
L’essor rapide des API, des plateformes low-code et des services SaaS accentue encore ce phénomène. Chaque brique intégrée ajoute un risque de dépendance supplémentaire. Les géants de la tech, malgré des ressources considérables, ne peuvent internaliser l’ensemble de ces fonctions. Ils deviennent alors eux-mêmes tributaires d’écosystèmes qu’ils ne contrôlent qu’en partie.
Un enjeu de résilience, mais aussi de confiance
Lorsque ces dépendances deviennent visibles — souvent lors d’une interruption de service — elles soulèvent des questions sur la confiance accordée aux infrastructures numériques globales. Pour les entreprises opérant dans des secteurs sensibles, la continuité de service n’est pas seulement un impératif commercial, mais aussi un enjeu réglementaire. Une interruption causée par un fournisseur externe peut entraîner des impacts contractuels, des risques réglementaires ou une perte de crédibilité auprès des clients finaux.
Le phénomène touche également l’IA générative et les services de calcul avancés. Les modèles les plus performants, utilisés par des millions d’utilisateurs, reposent eux aussi sur des chaînes techniques partiellement externalisées : c’est la preuve que la dépendance n’épargne plus aucun domaine, même les plus stratégiques.
Vers une nouvelle approche de la résilience numérique
Réduire la dépendance aux infrastructures cloud ne signifie pas revenir à un modèle totalement internalisé. En revanche, il devient nécessaire de repenser la manière dont les entreprises conçoivent leur architecture. L’objectif n’est pas de multiplier les fournisseurs pour “faire du multi-cloud” en théorie, mais de comprendre quelles briques méritent une diversification réelle, quelle autonomie minimale doit être préservée en cas d’incident, et quelles dépendances indirectes méritent d’être cartographiées et surveillées.
Cette approche nécessite une culture technique différente : plus transparente, plus consciente des chaînes d’interdépendances, et moins naïve face aux promesses de résilience totale souvent associées au cloud. Les entreprises les plus avancées commencent à intégrer des modes dégradés autonomes, à diversifier les points critiques comme le DNS ou l’authentification, et à revoir la manière dont elles confient leurs fonctions essentielles à des prestataires extérieurs.
Conclusion
La dépendance des géants de la tech aux infrastructures cloud n’est ni accidentelle ni temporaire. Elle est devenue un élément constitutif de l’économie numérique. Cette dépendance apporte puissance et efficacité, mais expose aussi à des risques systémiques difficilement maîtrisables. Comprendre ces risques, reconnaître la complexité des chaînes techniques et repenser la notion de résilience dans un monde cloud-centré sont désormais des enjeux majeurs pour toute organisation qui souhaite garantir la continuité de ses services et la confiance de ses utilisateurs.

Les murs anti-drones : l’urgence d’un rattrapage stratégique
Ces derniers jours, plusieurs aéroports européens — au Danemark, en Suède et en Allemagne — ont été contraints d’interrompre ou de perturber leurs activités à cause de drones non identifiés. Ces survols, parfois prolongés, ne sont pas de simples provocations : ils ressemblent davantage à des tests de vulnérabilité. Chaque incident envoie un message limpide : nos infrastructures critiques sont exposées, et il est aujourd’hui possible de paralyser une capitale européenne avec quelques appareils bon marché.
Un drone à 500 euros peut coûter plusieurs millions à un aéroport en une seule après-midi.
Un savoir-faire né de la guerre en Ukraine
La guerre en Ukraine a été un révélateur brutal. Les drones n’y sont pas seulement des instruments d’observation : ils sont devenus des armes de précision, des plateformes de reconnaissance et des munitions rôdeuses. Des quadricoptères civils modifiés guident les tirs d’artillerie ou larguent des grenades, tandis que des drones kamikazes à longue portée saturent les défenses adverses.
Trois leçons ressortent de ce conflit :
La démocratisation de la guerre aérienne, où quelques centaines d’euros suffisent à rivaliser avec des systèmes valant des millions ;
La saturation des défenses par des vagues de drones low-cost ;
Et la montée en autonomie, qui réduit l’efficacité du brouillage classique.
L’Ukraine est ainsi devenue un laboratoire grandeur nature, dont les enseignements se diffusent déjà au-delà du champ de bataille.
L’exemple iranien : produire simple, frapper fort
L’Iran a pris une avance stratégique en investissant massivement dans des drones peu coûteux, simples, mais produits à grande échelle. Les Shahed-136, utilisés en Ukraine par la Russie, incarnent cette logique : des engins robustes, capables de parcourir des centaines de kilomètres, dotés d’une charge explosive, et surtout fabriqués en série à des prix dérisoires.
La quantité a remplacé la sophistication comme critère de puissance.
Cette stratégie a permis à Téhéran de devenir fournisseur pour Moscou et pour d’autres alliés, diffusant un savoir-faire qui change les équilibres militaires. Pendant ce temps, l’Europe, fragmentée et lente, a laissé passer une décennie critique.
Les aéroports : premières victimes de cette asymétrie
Les survols observés à Copenhague, Stockholm ou Hambourg ces derniers jours ne sont probablement pas des erreurs isolées. Ils ressemblent davantage à des opérations de reconnaissance : observer, filmer, cartographier les réactions des forces de sécurité, tester les temps de réponse.
Un seul drone peut immobiliser un aéroport entier, interrompre des dizaines de vols et causer des pertes colossales. Plus grave encore, ces survols sapent la confiance du public et révèlent à quel point l’Europe a négligé sa défense civile face à cette nouvelle génération de menaces.
Les murs anti-drones : promesses et limites
Pour répondre à cette menace, des solutions dites de « murs anti-drones » se déploient peu à peu. Elles combinent radars, caméras thermiques, capteurs radio et IA de détection, avec des contre-mesures allant du brouillage à la neutralisation physique (filets, intercepteurs, lasers).
Leur efficacité est indéniable, mais leur coût et leur complexité freinent leur déploiement. Équiper un aéroport complet peut nécessiter plusieurs dizaines de millions d’euros et une coordination réglementaire délicate. Les systèmes doivent évoluer sans cesse, car chaque avancée technologique côté défense entraîne une contre-innovation côté attaque.
La défense doit devenir économique et modulaire, sinon elle perdra la guerre des coûts.
L’urgence du rattrapage
L’Europe n’a plus le luxe du temps. Les États qui ont anticipé — Iran, Turquie, Israël, Chine — exportent désormais leur savoir-faire et redessinent les équilibres militaires mondiaux. Pendant ce temps, nos capitales sont vulnérables à des drones qui, dans certains cas, coûtent moins qu’un smartphone.
Rattraper ce retard signifie agir immédiatement :
Investir massivement dans des systèmes anti-drones modulaires et interconnectés,
Mutualiser les achats au niveau européen pour réduire les coûts,
Adapter le cadre légal pour autoriser l’emploi de brouilleurs et de moyens militaires en contexte civil,
Former et entraîner régulièrement les opérateurs de sécurité à ces scénarios.
Ne pas agir maintenant, c’est accepter qu’un essaim de drones puisse, demain, immobiliser une capitale entière.
Conclusion : un choix de souveraineté
Nous vivons un moment charnière. Les drones ont déjà redessiné le champ de bataille en Ukraine et démontré leur efficacité stratégique. Les survols récents dans les aéroports du Danemark, de Suède et d’Allemagne montrent que cette réalité est désormais à nos portes.
Soit l’Europe rattrape son retard maintenant, soit elle restera spectatrice impuissante face à une menace qui se renforce chaque jour.

Cyberattaques en Belgique : quand la guerre hybride s’invite aux portes de l’Europe
Une menace qui dépasse la technique
La Belgique a connu plusieurs cyberattaques majeures ces dernières années, visant des infrastructures critiques et stratégiques. En 2021, l’attaque contre Belnet a paralysé le réseau reliant les administrations, universités et centres de recherche. Plus récemment, des attaques ont visé des hôpitaux, des ports, mais aussi des sous-traitants de l’aéroport de Bruxelles, qui jouent un rôle clé dans la logistique et la sécurité aérienne.
Ces opérations, souvent attribuées à des acteurs liés à la Russie ou à la Chine, ne visent pas uniquement à bloquer un service : elles cherchent à tester la résilience du pays, à désorganiser temporairement des secteurs vitaux, et à instiller la peur dans la population.
La guerre hybride en action
Ces attaques s’inscrivent dans une stratégie de guerre hybride :
Psychologique : cibler un hôpital ou un sous-traitant de l’aéroport de Bruxelles provoque immédiatement un sentiment d’insécurité. Les citoyens comprennent que leurs déplacements ou leurs soins peuvent être perturbés à tout moment.
Stratégique : perturber les transports, ralentir le fret aérien ou maritime, bloquer temporairement des trains ou retarder des vols sont autant de moyens de démontrer la vulnérabilité d’un pays situé au cœur de l’Europe.
Opérationnelle : les attaquants testent la capacité de réaction. Chaque incident est une sorte d’“exercice grandeur nature” pour mesurer combien de temps il faut avant que les systèmes soient rétablis et que la coordination reprenne.
Le précédent des attentats de Bruxelles
L’histoire récente rappelle que la désorganisation des communications peut coûter des vies. Lors des attentats du 22 mars 2016 à Bruxelles, le réseau téléphonique avait été saturé. Cette perturbation a entravé la coordination des secours : des ambulances et des équipes médicales n’ont pas pu être déployées efficacement, retardant la prise en charge de victimes graves.
Une attaque cyber ciblant les réseaux de communication ou les systèmes de gestion des urgences pourrait reproduire, voire amplifier, ce type de chaos – sans qu’aucune bombe n’explose.
Pourquoi la Belgique est un terrain d’essai
La Belgique concentre plusieurs atouts et vulnérabilités :
Institutions internationales : l’OTAN et l’Union européenne à Bruxelles font du pays une cible symbolique.
Infrastructures interconnectées : le port d’Anvers, l’aéroport de Bruxelles et les réseaux ferroviaires sont vitaux pour l’économie européenne. Une panne, même brève, peut perturber l’ensemble de la chaîne logistique.
Écosystème de sous-traitance : de nombreux services critiques (sécurité, bagages, systèmes IT aéroportuaires) sont gérés par des prestataires privés, souvent moins protégés que les institutions centrales, ce qui en fait une porte d’entrée privilégiée pour les attaquants.
Conséquences pour les citoyens et l’État
Les impacts potentiels dépassent la simple technique :
Perte de confiance : un citoyen qui ne peut pas voyager, recevoir des soins ou communiquer en urgence doute de la capacité de l’État à le protéger.
Risque d’escalade : une attaque de test aujourd’hui peut se transformer demain en attaque coordonnée, paralysant transports, hôpitaux et communication.
Impact économique : une cyberattaque sur le port d’Anvers ou sur l’aéroport de Bruxelles pourrait coûter des dizaines de millions d’euros par jour en pertes logistiques et commerciales.
La nécessité d’une cybersécurité renforcée
Pour répondre à cette menace, trois axes sont essentiels :
Coordination nationale : renforcer le rôle du Centre pour la Cybersécurité Belgique (CCB) et lier davantage les opérateurs de transport, d’énergie et de santé dans les plans de crise.
Investissements massifs : consacrer des budgets équivalents à ceux de la défense classique, car une cyberattaque peut paralyser un pays aussi sûrement qu’un missile.
Culture cyber : former les entreprises et les citoyens aux réflexes de sécurité. Une campagne de sensibilisation nationale, associée à des exercices de crise, peut limiter les dégâts d’une attaque réelle.
Conclusion
Les cyberattaques récentes ne sont pas des incidents isolés. Elles s’inscrivent dans une stratégie de guerre hybride, visant à intimider, perturber et tester les défenses d’un pays au cœur de l’Europe.
La Belgique, carrefour logistique et diplomatique, doit investir massivement dans sa résilience numérique. Car la prochaine attaque pourrait ne pas viser uniquement à faire peur, mais à désorganiser en profondeur les transports, la santé et la communication — avec des conséquences comparables à une attaque physique.

La cybersécurité, un tremplin pour les talents atypiques
La cybersécurité, un tremplin pour les talents atypiques
La cybersécurité est devenue l’un des enjeux majeurs de notre époque. Chaque jour, les entreprises font face à des attaques toujours plus sophistiquées, et les besoins en protection numérique explosent. Pourtant, un paradoxe persiste : malgré la multiplication des formations et des annonces d’emploi, les postes peinent à trouver preneurs. On parle de milliers de places vacantes en Belgique et en Europe. Pourquoi ? Parce que trop souvent, les filtres de recrutement restent figés sur un modèle unique : diplômes académiques, parcours linéaires, expériences validées. Et si cette vision était trop étroite ? Et si la cybersécurité avait justement besoin de talents venus d’ailleurs, de profils autodidactes, atypiques, parfois inattendus ?
Quand la compétence dépasse le diplôme
Dans le monde numérique, ce ne sont pas toujours les diplômes qui font la différence, mais la curiosité, la passion et la capacité à apprendre vite. Combien de jeunes passionnés ont appris à sécuriser des systèmes en explorant par eux-mêmes, en contribuant à des forums spécialisés ou en participant à des compétitions de hacking éthique ? Combien d’autodidactes passent leurs soirées à décortiquer des lignes de code, à tester des scénarios d’attaque et à comprendre, par l’expérience, ce que d’autres mettent des années à théoriser ? Ces profils existent. Ils sont compétents. Mais trop souvent, on les écarte, faute de diplôme estampillé d’une grande école.
Réduire la cybersécurité à une liste de certifications, c’est passer à côté d’une ressource précieuse : la créativité. Un bon professionnel de la cybersécurité, ce n’est pas seulement quelqu’un qui connaît les normes, mais quelqu’un qui anticipe, qui improvise, qui sait se mettre dans la tête d’un attaquant pour mieux protéger. Et ces qualités se développent aussi bien dans un parcours académique que dans l’autodidaxie passionnée.
L’exemple britannique : transformer des trajectoires de vie
Le Royaume-Uni a montré qu’il est possible d’aller encore plus loin. Ces dernières années, plusieurs programmes pilotes ont été lancés dans les prisons pour former des détenus à la cybersécurité. L’idée peut surprendre, mais les résultats parlent d’eux-mêmes. Certains prisonniers, parfois condamnés pour des délits liés à l’informatique, avaient déjà des compétences impressionnantes. D’autres ont découvert dans la cybersécurité une véritable vocation. Encadrés, accompagnés, ces profils se révèlent motivés, rigoureux et extrêmement loyaux envers les entreprises qui leur donnent une chance.
Ce modèle est inspirant : il prouve que même dans les contextes les plus éloignés du marché du travail traditionnel, il est possible de révéler et de valoriser des compétences utiles à la société. Si l’on peut faire confiance à des personnes en réinsertion, pourquoi continuer à fermer la porte à des candidats “hors norme” qui, sans diplôme, ont pourtant les qualités nécessaires pour réussir ?
Une richesse pour les entreprises
Donner leur chance à ces profils atypiques n’est pas une option par défaut face à la pénurie : c’est une véritable opportunité. Ces talents apportent un regard neuf, une capacité d’adaptation et une créativité que l’on retrouve moins chez des profils formatés. Ils savent communiquer, vulgariser, ou gérer des situations inédites, parce qu’ils viennent d’autres horizons : enseignement, artisanat, armée, commerce, ou même parcours autodidacte pur.
Pour les entreprises, c’est un pari qui rapporte. Non seulement elles comblent un besoin critique, mais elles renforcent aussi leur culture interne. Ces collaborateurs, conscients de la chance qui leur est donnée, font souvent preuve d’une loyauté rare. Dans un secteur où la confiance et la résilience sont des valeurs cardinales, c’est un atout immense.
Ouvrir les portes, changer les regards
La pénurie de talents en cybersécurité ne sera pas résolue uniquement par les universités ou les certifications prestigieuses. Elle passera par un changement de mentalité : accepter que la compétence se prouve autrement que par un diplôme, créer des parcours de reconversion accessibles, valoriser l’expérience pratique et la passion. Dans une société plurielle, il est urgent de sortir du réflexe “diplôme à tout prix” et d’ouvrir d’autres chemins vers la réussite professionnelle.
Cela suppose aussi une évolution de l’éducation. Les compétences numériques et la sensibilisation à la cybersécurité devraient être présentes dès l’école primaire, pour donner le goût et les bases à tous les enfants. Mais cela ne doit pas se traduire par l’obligation d’un long parcours universitaire. Cinq ans sur les bancs d’une faculté ne sont pas le seul moyen d’accéder à ces métiers. Des formations plus courtes, plus pratiques et mieux intégrées dans le tissu économique doivent permettre à chacun de trouver sa place, qu’il soit étudiant, en reconversion ou autodidacte.
En ouvrant la cybersécurité à des talents atypiques, nous faisons plus que combler des postes. Nous renforçons la diversité, nous enrichissons la réflexion stratégique et nous offrons à des individus une vraie place dans la société numérique. La cybersécurité est un enjeu collectif : elle mérite que l’on mobilise toutes les énergies, y compris celles qui ne rentrent pas dans les cases traditionnelles.

Phishing : de l’email frauduleux à l’arme numérique multi-canaux et réputationnelle
Le phishing, menace persistante et en pleine mutation
Il y a 20 ans, le phishing se résumait souvent à un email maladroit imitant une banque, incitant à cliquer sur un lien douteux pour “mettre à jour ses informations”.
Aujourd’hui, ce type d’attaque est devenu une opération sophistiquée et multicanale, capable d’utiliser des données personnelles précises, obtenues à la faveur de cyberattaques ciblées ou de fuites massives, pour tromper même les utilisateurs les plus vigilants.
Quand une fuite alimente une attaque
L’actualité récente en Italie illustre parfaitement le problème.
En août 2025, l’Agence italienne pour le numérique (Agid) a révélé le vol de près de 100 000 documents d’identité auprès d’une dizaine d’hôtels. Passeports, cartes d’identité, documents de check-in… tous en haute résolution, récupérés via des accès non autorisés entre juin et août 2025, puis mis en vente sur le dark web par un pirate connu sous le pseudonyme mydocs.
Ces données, déjà prêtes à l’emploi, permettent de :
- créer des campagnes de phishing hyper-ciblées (spear phishing) utilisant de vraies infos personnelles (nom, dates, destination du séjour, etc.) ;
- se livrer à l’usurpation d’identité pour des fraudes financières ;
- monter des scénarios de social engineering impossibles à distinguer d’un échange légitime.
Le glissement vers le “phishing réputationnel”
Traditionnellement, les cybercriminels ciblaient surtout des données chiffrées (bases de mots de passe, numéros de carte de crédit) à revendre ou à exploiter après décryptage.
Mais une tendance inquiétante s’impose : voler des données non chiffrées et exploitables immédiatement, car l’impact réputationnel sur l’entreprise victime fait souvent plus de dégâts — et plus vite — que la valeur marchande des données.
Ce que disent les rapports récents :
83 % des entreprises n’encryptent pas la majorité des données sensibles qu’elles stockent dans le cloud (Thales Cloud Security Study).
En 2024, des bases entières de données personnelles non chiffrées (38 Go) ont été retrouvées accessibles librement sur internet (TechRadar).
Une fuite majeure peut faire perdre 5 à 9 % de capital réputationnel à une marque (Oxford Academic), avec des impacts financiers et contractuels.
Les surfaces d’attaque actuelles
Le phishing n’est plus confiné à l’email. Les attaquants opèrent sur :
- Email : toujours le canal le plus répandu, mais avec des messages soignés, sans fautes, traduits automatiquement par IA.
- SMS / messageries instantanées (smishing, quishing) : liens courts, QR codes malveillants.
- Appels téléphoniques (vishing) : voix synthétiques imitant des interlocuteurs connus.
- Réseaux sociaux / plateformes professionnelles : faux profils, usurpation d’identité visuelle.
- Sites clones : pages web copiées à l’identique avec certificats HTTPS valides.
Les surfaces d’attaque du futur
Les tendances qui se dessinent pour les prochaines années sont préoccupantes :
- Deepfakes vocaux et vidéo : conversations vidéo avec un faux visage ou une voix imitée.
- Chatbots frauduleux : usurpation d’assistants IA d’entreprises pour tromper les clients.
- Phishing contextuel en temps réel : exploitation de données volées “juste après” un événement réel (réservation, paiement, déplacement).
- Attaques multi-canaux synchronisées : email + SMS + appel téléphonique pour rendre le scénario crédible.
Les données, carburant des attaques
Le lien entre fuite de données et phishing ciblé est direct.
Plus les données volées sont précises, plus l’attaque semble légitime.
Les criminels croisent plusieurs fuites pour construire un profil complet de la victime.
La frontière entre un message légitime et une attaque devient floue.
Comment réduire l’exposition
Côté entreprises:
- Collecter moins : limiter la conservation des données au strict nécessaires
- Chiffrer systématiquement les données sensibles au repos et en transit.
- Segmenter les systèmes : isoler les bases critiques et limiter les accès.
- Former le personnel : simulations régulières de phishing, sensibilisation aux signaux d’alerte.
- Surveiller le dark web pour détecter les fuites précocement.
Côté particuliers:
- Douter des urgences : vérifier tout message “urgent” par un canal officiel.
- Activer l’authentification multi-facteur partout où c’est possible.
- Contrôler ses données : utiliser des services de notification en cas de fuite (ex. Have I Been Pwned).
- Limiter le partage d’informations personnelles sur les réseaux.
Évolution du phishing et sophistication des données exploitées

2000–2010 Emails/login génériques Email Faible
2010–2020 Identifiants volés, logs simples Email, SMS, réseaux sociaux Moyenne
2020–2030 Scans identités, habitudes de vie Email, SMS, appels IA, deepfakes, chatbots Très élevée
Bibliographie
Thales Cloud Security Study – 83 % des entreprises n’encryptent pas toutes leurs données sensibles cloud.
TechRadar – 38 Go de données personnelles non chiffrées exposées en ligne.
Oxford Academic – Impact réputationnel de -5 à -9 % après une fuite majeure.
Axios – 1,7 milliard de notifications de fuite envoyées en 2024.
Tom’s Guide – 16 milliards d’identifiants exposés, alimentant des campagnes de phishing massives.
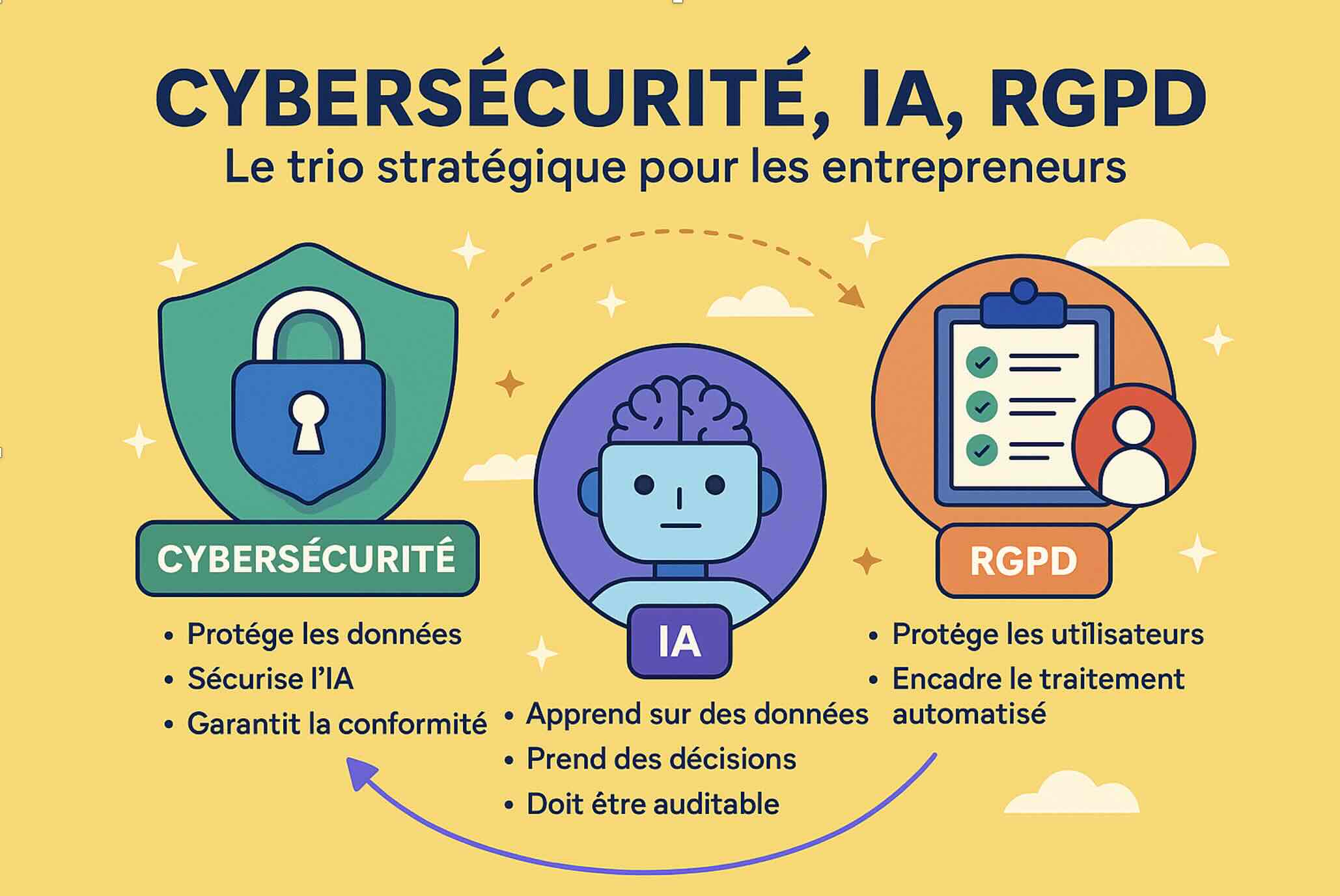
Cybersécurité, IA, RGPD : le trio stratégique que tout entrepreneur doit maîtriser
Cybersécurité, IA, RGPD : le trio stratégique que tout entrepreneur doit maîtriser
À l’ère du numérique intelligent, les entrepreneurs ne peuvent plus ignorer trois piliers qui conditionnent leur croissance et leur crédibilité : la cybersécurité, l’intelligence artificielle et la conformité RGPD.
Ces sujets ne sont plus l’affaire exclusive des juristes, des RSSI ou des data scientists. Ils sont devenus les fondations d’un modèle d’entreprise moderne, éthique et scalable. Et surtout, ils ne fonctionnent pas en silo : ils s’entrelacent profondément.
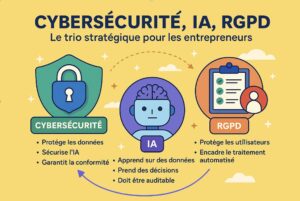
1. La cybersécurité : la base invisible mais vitale
Les startups et PME sont les premières victimes des cyberattaques. Un simple e-mail piégé, un mot de passe réutilisé ou un outil mal configuré peut ouvrir la porte à des rançongiciels, vols de données clients ou paralysie opérationnelle.
Ce que beaucoup ignorent, c’est que sans socle de sécurité robuste, il est impossible de se mettre en conformité RGPD ou de faire tourner une IA de façon éthique. L’infrastructure, les accès, le chiffrement : tout commence ici.
Un élément essentiel souvent négligé est le **pentesting** (test d’intrusion). Il permet de simuler des attaques réelles pour identifier les failles avant qu’elles ne soient exploitées. C’est un outil stratégique, non seulement pour sécuriser vos systèmes, mais aussi pour démontrer votre vigilance à vos partenaires et clients.
Autre point crucial : la conformité à la directive **NIS2** (Network and Information Systems Directive 2). Applicable dès 2024, elle impose aux entreprises de secteurs critiques (mais aussi à de nombreuses PME fournisseurs de services numériques) de se doter de mesures de cybersécurité robustes, de notifier les incidents, et de prouver leur résilience opérationnelle.
2. L’IA : puissante, mais fragile sans règles
L’intelligence artificielle peut devenir un accélérateur incroyable : automatisation, personnalisation, analyse prédictive… Mais elle repose sur des données (souvent personnelles), et prend des décisions (parfois sensibles).
L’AI Act impose désormais des obligations fortes : transparence, auditabilité, documentation, robustesse. Sans cybersécurité pour éviter la corruption des modèles ou les fuites de données, et sans RGPD pour encadrer les données d’entraînement, votre IA devient un risque juridique et réputationnel.
3. Le RGPD : bien plus qu’un cadre légal
Souvent vu comme un frein, le RGPD est en réalité une opportunité de structurer une relation saine avec vos utilisateurs et partenaires. En maîtrisant vos traitements de données, en respectant les droits des personnes (accès, rectification, suppression) et en garantissant un haut niveau de sécurité, vous gagnez en crédibilité.
Pourquoi Varden peut vous aider
Mettre en œuvre ce triptyque demande des compétences pointues, une vision transversale et une veille constante sur les règlementations. C’est là qu’intervient Varden Security, une société spécialisée dans la cybersécurité proactive, l’accompagnement réglementaire et les environnements IA sécurisés.
Varden propose : des solutions de sécurité managées adaptées aux PME et startups, des audits pour la conformité RGPD et NIS2, du pentesting, et un accompagnement expert pour fiabiliser vos projets IA dès leur conception.
En résumé
Ce ne sont pas trois chantiers séparés. Ce sont trois dimensions d’une même maturité numérique. Celles et ceux qui l’ont compris prennent de l’avance – pas seulement pour éviter les amendes, mais pour créer une entreprise résiliente, durable, et alignée avec les exigences du XXIe siècle.
Screenshot

IA, consentement et contrôle : Qui possède votre trace numérique en 2025 ?
En 2025, l’intelligence artificielle ne repose plus uniquement sur des données explicites.
Elle s’épanouit à partir de signaux que nous ignorons émettre — des schémas de comportement, le ton de notre voix, nos habitudes de défilement, les micro-délai dans notre frappe. Ces fragments, assemblés par des modèles d’apprentissage automatique, forment ce que l’on appelle de plus en plus notre « trace numérique ».
Cette ombre numérique n’est pas une simple métadonnée.
C’est une simulation en temps réel de ce que vous êtes, utilisée pour prédire ce que vous ferez, ressentirez ou choisirez.
Et la véritable question aujourd’hui n’est plus de savoir si nous sommes observés, mais bien si nous conservons notre libre arbitre dans un monde où l’IA interprète et agit en notre nom — souvent sans notre connaissance ni notre consentement.
Le profil invisible
Les préoccupations traditionnelles liées à la vie privée portaient sur les fuites de données, les mots de passe piratés ou les cookies intrusifs.
En 2025, la menace est plus subtile et systémique : l’inférence.
Les systèmes d’IA ne se contentent plus de stocker vos données :
ils construisent des profils comportementaux complexes pour anticiper vos décisions.
Qu’il s’agisse d’un service financier évaluant votre solvabilité ou d’un assistant numérique filtrant votre fil d’actualité, ces systèmes s’appuient sur des modèles probabilistes construits à partir de votre exhaust numérique.
Vous n’y avez pas forcément consenti — en tout cas, pas directement.
Mais le simple fait d’être en ligne entraîne mécaniquement ces modèles.
Le consentement par défaut
La collecte de données par les plateformes a évolué :
elle est passée d’un opt-in explicite à une passivité par défaut.
Les politiques de confidentialité sont opaques, les formulaires de consentement volontairement ambigus, et l’inférence algorithmique est rarement encadrée par la loi.
Pire encore, l’émergence d’analyses générées par l’IA — des scores de personnalité aux prédictions en santé mentale — crée une zone grise :
même si les données brutes vous appartiennent, les interprétations aussi ?
Dans la plupart des cadres juridiques, la réponse est floue.
Le RGPD, par exemple, régule les données personnelles, mais dit peu de choses sur les traits inférés ou les prédictions algorithmiques.
Ce vide juridique expose les utilisateurs à une nouvelle forme de colonialisme des données — où des machines extraient de la valeur à partir de notre comportement, sans que nous n’ayons jamais vu la carte.
La propriété algorithmique
Qui possède votre trace ?
-
Les courtiers en données disent : « c’est anonymisé ».
-
Les plateformes disent : « ce sont des inférences, pas des données ».
-
Les régulateurs disent : « nous travaillons dessus ».
Pendant ce temps, le profilage prédictif redéfinit l’accès à l’emploi, le scoring de crédit, les tarifs d’assurance ou le ciblage politique.
Une IA que vous ne rencontrerez jamais prend des décisions basées sur une version de vous qu’elle a elle-même construite —
un jumeau probabiliste que vous ne pouvez ni auditer ni corriger.
Ces profils IA doivent-ils être reconnus comme données personnelles ?
Les individus doivent-ils avoir le droit d’y accéder, de les supprimer, ou de les contester ?
Techniquement, c’est possible. Éthiquement, c’est indispensable. Légalement, nous sommes en retard.
Une voie à suivre
Des solutions émergent :
-
Apprentissage fédéré
-
Confidentialité différentielle
-
Coffres-forts de données contrôlés par l’utilisateur
Mais le vrai défi n’est ni technique, ni juridique :
il est politique et culturel.
Nous devons repenser la notion d’agence numérique.
Le consentement ne peut être passif.
Le profilage ne peut être invisible.
L’IA ne peut pas agir en votre nom sans mécanisme de contrôle ou de recours.
Concevoir une véritable transparence impose de réinventer le design des interfaces, les modèles économiques et la gouvernance des données.
Cela signifie outiller les citoyens — pas seulement les entreprises — pour qu’ils puissent gérer leur présence numérique.
Conclusion : la nouvelle frontière des droits numériques
En 2025, les droits numériques ne se résument plus à ce que vous partagez consciemment.
Ils concernent ce que d’autres déduisent, synthétisent et exploitent — à partir des ombres que vous ignoriez avoir laissées derrière vous.

La CNIL vient de publier 13 fiches pratiques pour aider les entreprises, administrations et développeurs à concevoir des systèmes d’IA respectueux des droits fondamentaux.
L’intelligence artificielle avance vite, mais la régulation aussi.
La CNIL vient de publier 13 fiches pratiques pour aider les entreprises, administrations et développeurs à concevoir des systèmes d’IA respectueux des droits fondamentaux.
👉 Ce n’est pas un simple avis d’expert, mais une boîte à outils très opérationnelle, couvrant :
L’intérêt légitime et la base juridique des traitements IA
L’analyse d’impact (AIPD)
Les biais et discriminations
La transparence, l’explicabilité
Les données d'entraînement
La minimisation et conservation des données
Les droits des personnes (accès, opposition, etc.)
Les cas d'usage concrets (RH, cybersécurité, détection de fraude…)
🔍 Objectif : traduire le RGPD dans la pratique IA, sans freiner l’innovation.
Un excellent guide pour préparer son IA Act-compliant et anticiper les audits à venir.
📘 Lien vers les 13 fiches : https://www.itforbusiness.fr/la-cnil-finalise-ses-recommandations-sur-lia-93029

Introduction au Machine Learning avec Python : Votre Premier Modèle IA de A à Z
L'intelligence artificielle, souvent associée à des concepts abstraits et complexes, devient accessible grâce à Python. Aujourd’hui, vous allez découvrir comment créer un modèle de machine learning qui apprend à prédire si un passager du Titanic a survécu ou non. Ce projet concret vous donnera une vraie compréhension de ce qu’est l’IA appliquée.
Étape 1 : Comprendre les données et le rôle de df
Dans ce tutoriel, nous utilisons un jeu de données très célèbre : celui du Titanic. Chaque ligne représente un passager, avec des colonnes comme son âge, son sexe, sa classe dans le bateau, le prix payé pour son billet, et surtout, s’il a survécu (Survived = 1) ou non (Survived = 0).
Quand on lit ce fichier CSV avec pandas, on stocke les données dans une structure appelée DataFrame, abrégée en df. Un DataFrame est un tableau à deux dimensions : les colonnes sont les variables (âge, sexe…), et chaque ligne est un exemple (un passager). Voici comment on charge ce fichier :
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
print(df.head())Étape 2 : Nettoyage des colonnes – pourquoi et comment
Le jeu de données brut contient beaucoup de colonnes inutiles ou incomplètes. Par exemple, les colonnes Name, Ticket, ou Cabin sont peu pertinentes pour notre tâche. De plus, certaines lignes n’ont pas de valeur dans la colonne Age.
Nous allons donc :
- Sélectionner les colonnes pertinentes :
Pclass(classe sociale),Sex,Age,Fare, et la cibleSurvived. - Remplacer les valeurs manquantes dans la colonne
Agepar la médiane. - Convertir les valeurs textuelles (comme "male" et "female") en nombres.
df = df[['Pclass', 'Sex', 'Age', 'Fare', 'Survived']]
df['Age'].fillna(df['Age'].median(), inplace=True)
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})Étape 3 : Séparation entre variables explicatives et cible
Le machine learning fonctionne ainsi : on donne au modèle des entrées (par exemple Age, Sex, Fare) et on lui demande d’apprendre à prédire une sortie(Survived). On sépare donc notre tableau en deux :
X = df[['Pclass', 'Sex', 'Age', 'Fare']]
y = df['Survived']Ensuite, pour bien évaluer notre modèle, on le teste sur des données qu’il n’a jamais vues :
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Étape 4 : Entraînement du modèle
On utilise ici un arbre de décision, un algorithme simple mais très efficace pour des jeux de données de ce type :
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)Étape 5 : Évaluation de la précision
On peut maintenant mesurer la qualité de notre modèle :
from sklearn.metrics import accuracy_score
y_pred = model.predict(X_test)
print("Précision :", accuracy_score(y_test, y_pred))Étape 6 : Utilisation du modèle sur un cas réel
Imaginons que vous ayez un nouveau passager et que vous vouliez prédire s’il aurait survécu. Voici un exemple :
import numpy as np
# Exemple : femme de 29 ans, en 2e classe, billet à 25 €
nouveau_passager = np.array([[2, 1, 29, 25]])
prediction = model.predict(nouveau_passager)
print("Survivante" if prediction[0] == 1 else "Non survivante")Conclusion : vous venez de construire une intelligence artificielle
Vous avez vu comment charger des données, les nettoyer, entraîner un modèle, le tester, puis l’utiliser. Ce n’est pas de la théorie : c’est le cœur même du machine learning. Python rend cela accessible à tous, même sans être mathématicien ou ingénieur.
Le monde de l’IA ne vous est plus fermé. Il vous appartient maintenant de continuer à explorer, tester, modifier les paramètres, changer d’algorithme, et surtout : pratiquer.

Créer une API Météo Intelligente avec Python, IA et FastAPI
Ce projet consiste à créer une API REST moderne qui interroge un service météo en temps réel, puis applique un modèle de machine learning pour prédire la température dans les prochaines heures. Le tout est exposé via une interface web performante grâce à FastAPI.
🧠 Objectif de l'API
- Collecter les données météo d'une ville via l'API OpenWeatherMap
- Appliquer un modèle IA entraîné sur des données historiques
- Exposer les résultats sous forme d’API REST
🧰 Librairies utilisées
| Outil | Utilisation |
|---|---|
requests |
Appels HTTP à l'API météo |
pandas |
Manipulation de données |
scikit-learn |
Modélisation de la prédiction météo |
FastAPI |
Création de l’API REST |
uvicorn |
Serveur de développement performant |
pip install fastapi uvicorn requests pandas scikit-learn📡 Récupération des données météo
Le fichier suivant interroge OpenWeatherMap avec une clé API. Le retour est simplifié pour n’extraire que les champs utiles.
import requests
API_KEY = "VOTRE_CLE_API"
def get_weather(city):
url = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}&units=metric"
response = requests.get(url)
if response.status_code != 200:
raise Exception(f"Erreur API météo : {response.status_code}")
data = response.json()
return {
"city": city,
"temperature": data["main"]["temp"],
"humidity": data["main"]["humidity"],
"wind": data["wind"]["speed"],
"description": data["weather"][0]["description"]
}🤖 Modélisation IA avec scikit-learn
Le modèle de régression linéaire apprend à prédire la température future (dans 3h) à partir des conditions actuelles. Ce modèle est volontairement simple pour illustrer le concept.
import numpy as np
from sklearn.linear_model import LinearRegression
class WeatherPredictor:
def __init__(self):
self.model = LinearRegression()
def train(self, historical_data):
X = historical_data[["temperature", "humidity", "wind"]]
y = historical_data["temperature_in_3h"]
self.model.fit(X, y)
def predict(self, current):
features = np.array([[current["temperature"], current["humidity"], current["wind"]]])
return self.model.predict(features)[0]🚀 Création de l'API REST avec FastAPI
Le cœur du projet consiste à exposer un endpoint REST qui combine données météo en direct et prédiction. L’interface Swagger est automatiquement générée.
from fastapi import FastAPI
from weather_fetcher import get_weather
from ml_model import WeatherPredictor
import pandas as pd
app = FastAPI(
title="API Météo IA",
description="Prévisions météo avec FastAPI et scikit-learn",
version="1.0"
)
historical = pd.DataFrame([
{"temperature": 20, "humidity": 65, "wind": 5, "temperature_in_3h": 21.5},
{"temperature": 25, "humidity": 55, "wind": 3, "temperature_in_3h": 26.5},
{"temperature": 30, "humidity": 45, "wind": 2, "temperature_in_3h": 32.0},
{"temperature": 15, "humidity": 80, "wind": 6, "temperature_in_3h": 16.5}
])
model = WeatherPredictor()
model.train(historical)
@app.get("/predict/{city}")
def predict(city: str):
try:
current = get_weather(city)
predicted = model.predict(current)
return {
"city": city,
"current_weather": current,
"predicted_temperature_in_3h": round(predicted, 2)
}
except Exception as e:
return {"error": str(e)}💻 Lancement local
uvicorn main:app --reloadAccessible ensuite via l’interface interactive : http://localhost:8000/docs
🛠️ Améliorations possibles
- Connexion à une base de données (SQLite, PostgreSQL)
- Entraînement sur des données météo réelles
- Sérialisation du modèle avec joblib
- Système de cache pour éviter les appels API multiples
- Système d’authentification JWT pour sécuriser les endpoints
📁 Structure recommandée
project/
├── main.py
├── weather_fetcher.py
├── ml_model.py
├── requirements.txt
└── data/📌 Résumé
| Composant | Technologie utilisée |
|---|---|
| Récupération météo | requests + OpenWeatherMap |
| Prédiction IA | scikit-learn |
| API REST | FastAPI |
| Serveur | uvicorn |